시험 전 및 시험 후 확률
Pre- and post-test probability시험 전 확률과 시험 후 확률(대안 철자 사전 시험 및 시험 후 확률)은 각각 진단 시험 전후의 상태(질병 등)의 존재 확률이다. 시험 후 확률은 시험 결과가 각각 양성 시험으로 나오는지 음성 시험으로 나오는지에 따라 양성이거나 음성이 될 수 있다. 장래에 관심의 조건을 발전시킬 확률에 이용되는 경우도 있다.
이러한 의미에서 시험은 어떤 의학 시험(그러나 보통 진단 시험의 의미에서는)을 참조할 수 있으며, 넓은 의미에서는 질문이나 심지어 가정(예: 대상자가 여성 또는 남성이라고 가정하는 것)을 포함할 수도 있다. 다양한 조건의 사전 및 사후 시험 확률을 차이를 만드는 능력은 의료 시험 표시의 주요 요인이다.
시험 전 확률
개인의 사전 시험 확률은 다음 중 하나로 선택할 수 있다.
- 개인에게 다른 특성이 알려져 있지 않을 경우 선택해야 할 수도 있고, 그러한 누락으로 인해 부정확한 결과가 발생할 수 있지만 다른 특성이 알려져 있더라도 계산의 용이성을 위해 선택할 수 있는 질병의 유병률
- 하나 이상의 선행 테스트에서 발생하는 조건의 사후 테스트 확률
- 더 체계적인 접근이 불가능하거나 효율적인 경우 선택해야 할 수 있는 대략적인 추정
시험 후 확률 추정
임상 실습에서 시험 후 확률은 흔히 대략적으로 추정하거나 심지어 추측하기도 한다. 이는 대개 병리학적 기호나 증상의 발견에서 허용되며, 이 경우 대상 조건이 존재하는 것이 거의 확실하거나, 사인 쿼 비 기호나 증상이 없는 경우 대상 조건이 없는 것이 거의 확실하다.
그러나 실제로 어떤 조건이 존재할 때의 주관적 확률은 결코 정확히 0이나 100%가 아니다. 그러나, 그 확률을 추정하기 위한 몇 가지 체계적인 방법이 있다. 이러한 방법은 일반적으로 시험 수행 데이터를 확립하기 위해 조건의 유무를 알 수 있는 기준 그룹에 대해 이전에 시험을 수행한 적이 있거나(또는 "금색 표준"과 같이 매우 정확하다고 간주되는 다른 시험으로 추정됨)에 근거한다. 이 데이터는 이후 방법으로 시험한 개인의 시험 결과를 해석하는 데 사용된다. 참조 그룹 기반 방법의 대안 또는 보완은 동일한 개인에 대한 이전 시험과 시험 결과를 비교하는 것인데, 이것은 모니터링을 위한 시험에서 더 흔하다.
시험 후 확률을 추정하기 위한 가장 중요한 체계적 참조 그룹 기반 방법에는 다음 표에서 요약 및 비교한 방법 및 아래 개별 섹션에 자세히 설명되어 있는 방법이 포함된다.
| 방법 | 실적자료 설정 | 개별 해석 방법 | 후속 테스트를 정확하게 해석할 수 있는 능력 | 부가적 장점 |
|---|---|---|---|---|
| 예측 값 기준 | 참조 그룹의 직접 인용구 | 가장 간단함: 예측 값은 확률과 동일함 | 일반적으로 낮음: 이후의 모든 사전 테스트 상태에 대해 별도의 참조 그룹이 필요 | 이진수 및 연속수 값에 모두 사용 가능 |
| 우도비별 | 민감성 및 특수성에서 파생됨 | 사전 테스트 오즈를 비율에 곱하여 얻은 테스트 후 오즈 | 이론상 무제한 | 테스트 전 상태(따라서 테스트 전 확률)는 참조 그룹과 동일할 필요가 없음 |
| 상대위험별 | 노출된 위험과 노출되지 않은 위험의 비율 | 테스트 전 확률에 상대 위험 곱하기 | 후속 상대 위험이 동일한 다변량 회귀 분석에서 도출되지 않는 한 낮음 | 비교적 사용하기 직관적 |
| 진단 기준 및 임상 예측 규칙에 따라 | 가변적이지만 일반적으로 가장 지루함 | 변수 | 일반적으로 기준에 포함된 모든 테스트에서 우수함 | 일반적으로 사용 가능한 경우 가장 선호됨 |
예측 값 기준
예측 값은 개인의 사전 시험 확률을 조건의 유무에 대한 시험 결과와 지식(예: "골드 표준"에 의해 결정될 수 있는 질병)을 모두 가진 기준 그룹의 유병률과 대략 같다고 가정할 수 있는 경우 개인의 시험 후 확률을 추정하는 데 사용할 수 있다. 이용 가능하다.
시험 결과가 양 또는 음의 시험으로 이항 분류된 경우, 다음 표를 작성할 수 있다.
| 조건 ("골드 표준"에 의해 결정됨) | ||||
| 긍정적인 | 네거티브 | |||
| 테스트 결과 | 긍정적인 | 트루 포지티브 | 거짓 긍정 (I형 오류) | → 긍정적 예측가치 |
| 네거티브 | 거짓 음성 (타입 II 오류) | 트루 네거티브 | → 마이너스 예측값 | |
| ↓ 민감도 | ↓ 특수성 | ↘ 정확도 | ||
시험 전 확률은 다음과 같이 도표에서 계산할 수 있다.
사전 테스트 확률 = (참 양수 + 거짓 음수) / 총 샘플
또한 이 경우 양성반응 후 확률(시험이 양성으로 빠질 경우 목표조건이 있을 확률)은 양의 예측값과 수치적으로 같으며, 음성반응 후 확률(시험이 음성으로 빠질 경우 목표조건이 있을 확률)은 음수와 수적으로 상호보완된다.tive 예측 값([음성 테스트 후 확률] = 1 - [음성 예측 값]))[1]을 다시 가정하면, 테스트 대상 개인이 테스트의 양의 예측 값과 음의 예측 값을 설정하는 데 사용된 기준 그룹과 다른 사전 테스트 확률을 갖는 다른 위험 인자가 없다고 가정한다.
위의 다이어그램에서 양성 시험 결과가 주어진 목표 조건의 양성 시험 후 확률, 즉 양성 시험 후 확률은 다음과 같이 계산된다.
양성 테스트 후 확률 = 참 양성 / (참 양성 + 거짓 양성)
이와 유사하게:
음성 결과가 주어지는 질병의 시험 후 확률은 다음과 같이 계산된다.
음성 검사 후 확률 = 거짓 음성 / (거짓 음성 + 참 음성)
위의 방정식의 유효성은 또한 모집단의 표본이 해당 모집단의 해당 유병률과 "비유병성"으로부터 실질적으로 불균형하지 않은 모집단의 집단을 만드는 실질적인 표본추출편향을 가지고 있지 않은지에 따라 결정된다. 실제로 위의 방정식은 조건이 있는 한 그룹과 조건이 없는 한 그룹을 별도로 수집하는 환자-대조군 연구만으로는 유효하지 않다.
우도비별
위의 방법은 시험 전 확률이 시험의 양성 예측 값을 설정하기 위해 사용된 기준 그룹의 유병률과 다를 경우 사용하기에 부적절하다. 이러한 차이는 다른 검사가 선행되거나 진단에 참여한 사람이 예를 들어 특정 불만사항, 의료기록의 다른 요소, 신체검사에서 사인 등을 알고 있기 때문에 다른 사전시험 확률을 사용해야 한다고 판단하는 경우 발생할 수 있다. 민감도와 특수성 또는 적어도 개별 사전 시험 확률의 대략적인 추정.
이러한 경우 기준 그룹의 유병률은 개인의 시험 전 확률을 나타내는 데 있어서 완전히 정확하지 않으며, 따라서 예측 값(긍정적이든 음적이든)은 목표 조건을 갖는 개인의 시험 후 확률을 나타내는 데 있어서 완전히 정확하지 않다.
이러한 경우 시험 후 확률은 시험의 우도비를 사용하여 더 정확하게 추정할 수 있다. 우도비는 검정의 민감도와 특수성에서 계산되며, 따라서 기준 그룹의 유병률에 의존하지 않으며,[2] 마찬가지로 양성 또는 음성 예측 값(변하게 될)과는 대조적으로 시험 전 확률을 변경해도 변하지 않는다. 또한 실제로 우도비에서 결정되는 시험 후 확률의 유효성은 모집단 표본의 조건을 가진 사람과 그렇지 않은 사람과 관련하여 표본추출편향에 취약하지 않으며, 조건을 가진 사람과 그렇지 않은 사람을 별도로 수집하는 사례관리 연구로서 수행될 수 있다.
시험 전 확률과 우도비에서 시험 후 확률을 추정하는 방법은 다음과 같다.[2]
- 사전 테스트 승산 = (예측 확률 / (1 - 사전 테스트 확률)
- 검사 후 승산 = 사전 검사 승산 *우도비
위의 방정식에서는 양성-검정 후 확률을 우도비 양성으로 계산하고 음성-검정 후 확률은 음성으로 계산한다.
- 시험 후 확률 = 시험 후 승산 / (시험 후 승산 + 1)

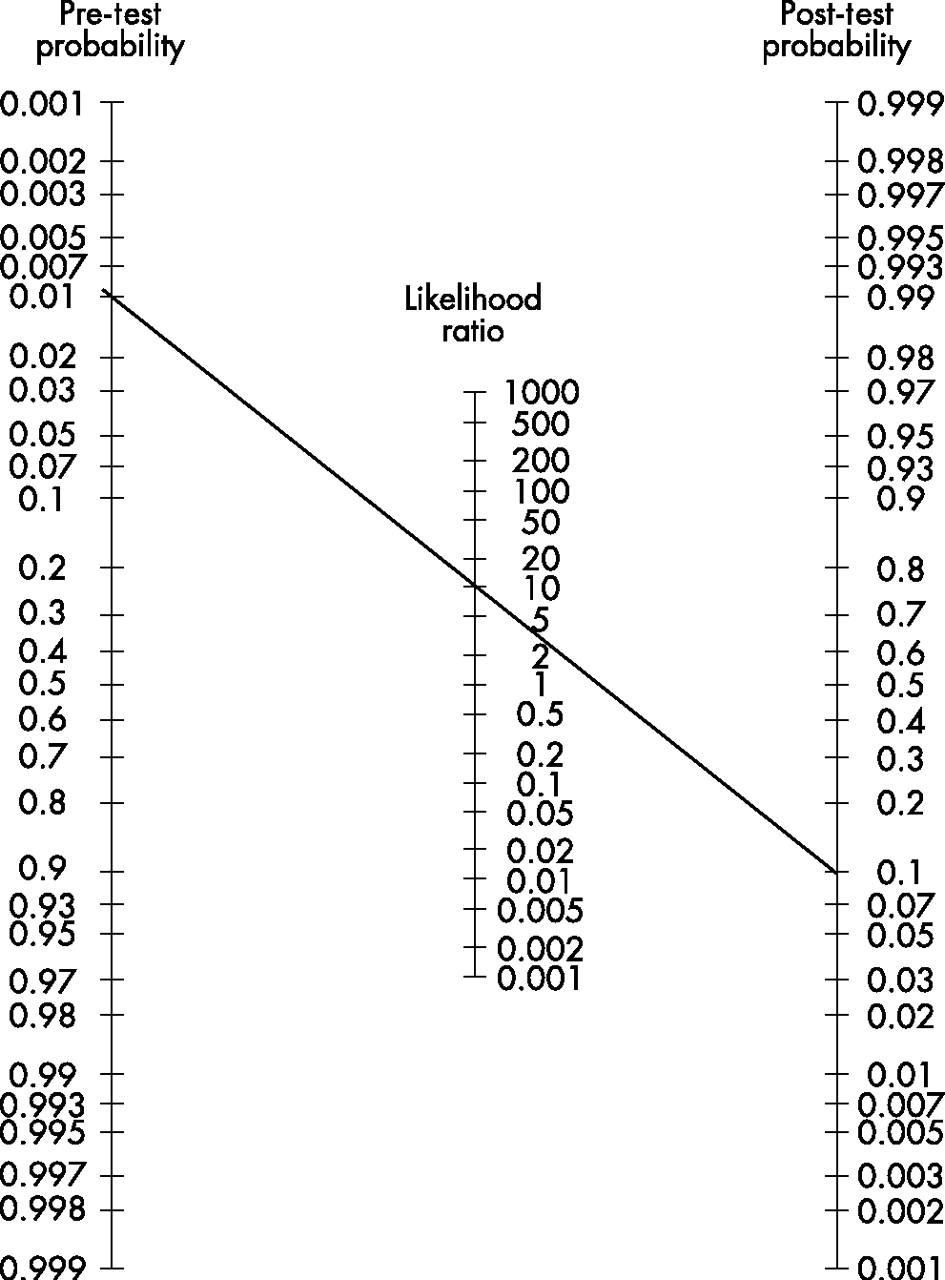
관계도 주어진 시험 전 확률의 지점에서 그 척도의 주어진 우도비까지의 직선을 만들어 소위 Fagan 노모그램(오른쪽 표시)으로 추정할 수 있으며, 다시 그 직선이 척도를 교차하는 지점에서 시험 후 확률을 추정한다.
시험 후 확률은 동일한 방식으로 계속 계산되는 경우 추가 시험에 대한 사전 시험 확률을 사용할 수 있다.[2]

녹색 곡선(왼쪽 위)이 양의 시험을 나타내고, 빨간색 곡선(오른쪽 아래 절반)이 음의 시험을 나타내는 것으로, 우도비 9와 음의 우도비 0.111에 해당하는 감도 및 특이도를 나타내는 다이어그램. 녹색 화살표의 길이는 양의 테스트가 주어진 절대(상대성이 아닌) 확률의 변화를 나타내며, 빨간색 화살표는 음의 테스트가 주어진 절대 확률의 변화를 나타낸다.
화살표의 길이에서 볼 수 있는 것은 낮은 사전 시험 확률에서 양성 시험이 음성 시험보다 절대 확률에 더 큰 변화를 준다는 것을 알 수 있다(특정성이 민감도보다 그리 높지 않은 한 일반적으로 유효하다). 마찬가지로, 높은 시험 전 확률에서 음성 시험은 양의 시험(감도가 특이성보다 그리 높지 않은 한 일반적으로 유효한 속성)보다 절대 확률에 더 큰 변화를 준다.
다양한 우도비 양성(왼쪽 위)에 대한 사전 및 사후 테스트 확률과 다양한 우도비 음성(오른쪽 아래) 간의 관계.


연속 값 또는 이분법 결과에 대한 계산과 유사한 세 개 이상의 결과를 갖는 검정에 대한 우도비 계산을 수행할 수 있다. 이를 위해 시험 결과의 모든 수준에 대해 별도의 우도비를 계산하고 구간 또는 층별 고유우도비라고 한다.[4]
예
한 개인은 장암의 목표 조건을 가진 사람의 확률을 추정하기 위해 분변 오컬트 혈액 검사(FOB)로 검사되었고 양성 반응이 나왔다(변에서 혈액이 검출되었다). 시험 전에, 그 개인은 예를 들어, 3%(0.03)의 대장암에 걸릴 확률을 가지고 있었다. 예를 들어, 의료 기록, 검사 및 이전 시험의 평가로 추정할 수 있었다.
FOB 검사의 민감도, 특수성 등은 203명의 모집단 표본(그런 유전이 없는 경우)으로 확립되어 다음과 같이 탈락하였다.
| 대장암 환자 (내시경 검사에서 확인됨) | ||||
| 긍정적인 | 네거티브 | |||
| 대변 오컬트 핏덩어리 스크린을 하다 시험하다 결과 | 긍정적인 | TP = 2 | FP = 18 | → 긍정적 예측가치 = TP / (TP + FP) = 2 / (2 + 18) = 2 / 20 = 10% |
| 네거티브 | FN = 1 | TN = 182 | → 마이너스 예측값 = TN / (FN + TN) = 182 / (1 + 182) = 182 / 183 ≈ 99.5% | |
| ↓ 민감도 = TP / (TP + FN) = 2 / (2 + 1) = 2 / 3 ≈ 66.67% | ↓ 특수성 = TN / (FP + TN) = 182 / (18 + 182) = 182 / 200 = 91% | ↘ 정확도 = (TP + TN) / 합계 = (2 + 182) / 203 = 184 / 203 = 90.64% | ||
이로부터 시험의 우도비를 다음과 같이 설정할 수 있다.[2]
- 우도비 양성 = 민감도 / (1 - 특수도) = 66.67% / (1 - 91%) = 7.4
- 우도비 음수 = (1 - 민감도) / 특이도 = (1 - 66.67%) / 91% = 0.37
- 사전 테스트 확률(이 예에서는) = 0.03
- 사전 테스트 오즈 = 0.03 / (1 - 0.03) = 0.0309
- 양성 테스트 후 승산 = 0.0309 * 7.4 = 0.229
- 양성반응후확률 = 0.229 / (0.229 + 1) = 0.186 또는 18.6%
따라서 이 개인은 대장암에 걸릴 확률이 18.6%에 이른다.
모집단 표본의 유병률은 다음과 같이 계산된다.
- 유병률 = (2 + 1) / 203 = 0.0148 또는 1.48%
비록 개인의 시험 후 확률은 모집단 표본의 2배(검정의 양의 예측값으로 추정됨)보다 작았지만, 단순히 상대성을 곱하는 덜 정확한 방법에 의해 초래되는 것과는 정반대였다.나는 위험이 있다.
부정확성의 특정 원인
시험 후 확률을 결정하기 위해 우도비를 사용할 때 특정 부정확성의 원천에는 다음과 같이 결정 요인이나 이전 시험 또는 시험 대상의 중복에 대한 간섭이 포함된다.
테스트 간섭
우도비를 가진 시험 전 확률로 추정된 시험 후 확률은 일반 모집단보다 다른 결정인자(예: 위험인자)를 가진 개인뿐만 아니라 이전 시험을 거친 개인에서도 주의 깊게 다루어야 한다. 그러한 결정인자나 시험은 시험 자체에 영향을 미칠 수 있기 때문이다.교묘한 방법, 여전히 부정확한 결과를 초래한다. 비만의 위험 요인이 되고 예는 추가적인 복부 지방이 어려운 복부 초음파 검사의 해상도 감소 복부 기관 촉수가 있는 것과 이전 촬영에서 잔류 바륨 대비 후속들은 examinations,[5]과 효과의 민감성 감소하고 방해할 수 있게 만들 수 있고 있다.s그러한 후속 시험의 중요성 반면에, 간섭의 효과는 저체중 사람들에게 수행될 때 일부 복부 검사가 더 쉬워지는 것과 같이 기준 그룹에서 사용된 것과 비교하여 후속 시험의 유효성을 잠재적으로 개선할 수 있다.
테스트 중복
또한, 이전 시험에서 도출된 사전 시험 확률에 대한 계산의 유효성은 테스트 대상 파라미터와 관련하여 두 테스트가 유의하게 중복되지 않는다는 점에 따라 달라진다. 예를 들어, 한 테스트에 속하는 물질의 혈액 검사 및 동일한 비정상적인 대사 경로에 속하는 물질과 같은 것이다. 그러한 중첩의 극한 예는 "보조물 X"를 검출하는 혈액 검사와 마찬가지로 "보조물 Y"를 검출하는 혈액 검사에 대한 민감도와 특수성이 확립된 경우다. 실제로 "보조 X"와 "보조 Y"가 하나이고 같은 물질이라면, 계산에 차이가 있는 것처럼 보이지만, 동일한 물질과 하나의 물질을 연속적으로 두 번 검사하는 것은 전혀 진단값을 갖지 못할 수 있다. 위에서 설명한 간섭과 대조적으로, 시험의 중첩을 증가시키면 효과만 감소한다. 의료 환경에서 진단 유효성은 혈액 검사, 생체검사, 방사선 촬영 등을 조합하는 것과 같이 서로 다른 양식의 테스트를 조합하여 상당한 중복을 방지함으로써 증가한다.
부정확성을 극복하는 방법
우도비를 사용하여 그러한 부정확성의 원인을 방지하려면, 그러한 개인에서 시험을 사용하기 위한 별도의 예측 값을 설정하기 위해 등가 개인으로 구성된 큰 참조 그룹을 수집하는 것이 최적 방법일 것이다. 그러나 개인의 병력, 신체검사, 이전 시험 등에 대한 지식이 많아지면 개인별로 차이가 커지며, 맞춤형 예측값을 설정하기 위한 기준 집단을 찾기 어려워져 예측값에 의한 사후시험 확률 추정이 무효화된다.
이러한 부정확성을 극복하기 위한 또 다른 방법은 다음 절에서 설명한 것처럼 진단 기준의 맥락에서 시험 결과를 평가하는 것이다.
상대위험별
시험 후 확률은 시험 전 확률에 시험에 의해 주어진 상대적 위험을 곱하여 추정할 수 있다. 임상실무에서 이것은 대개 개인의 의료기록 평가에 적용되는데, 여기서 "시험"은 예를 들어 성, 흡연 또는 체중과 같은 다양한 위험요인에 관한 질문(또는 심지어 가정)이지만 잠재적으로 개인을 체중계에 올려놓는 것과 같은 실질적인 시험이 될 수 있다. 상대적 위험을 사용할 때, 결과적 확률은 일반적으로 현재 조건을 가진 개인의 확률은 아닌 일정 기간 동안(인구 발생률과 유사하게) 조건을 개발하는 개인과 관련이 있지만 간접적으로 후자의 추정일 수 있다.
위험비의 사용은 상대적 위험과 다소 유사하게 사용될 수 있다.
한 가지 위험 요인
상대적 위험을 설정하기 위해 노출된 그룹의 위험은 노출되지 않은 그룹의 위험으로 나눈다.
한 개인의 위험 요소만 고려한다면, 상대적 위험과 대조군 그룹의 위험을 곱하여 시험 후 확률을 추정할 수 있다. 대조군 집단은 일반적으로 노출되지 않은 모집단을 나타내지만, 모집단의 매우 낮은 비율이 노출되는 경우 일반 모집단의 유병률은 대조군 집단의 유병률과 같다고 가정할 수 있다. 이러한 경우, 시험 후 확률은 상대적 위험과 일반 모집단의 위험을 곱하여 추정할 수 있다.
예를 들어, 유방 암의 영국에서 나이 55세에서 59한 여자에서 이 사건 100.000당 year,[6]1인당 약 280경우에, 2.1사이에 유방 암의 상대적 위험 가능성을 부여의 위험 요인은 가슴( 다른 암들을 위한 치료 예를 들어,)에 전리 방사선 high-dose에 노출됬고로 추정된다. 4.0노출되지 않은 것과 비교하여.[7] 모집단의 적은 부분이 노출되기 때문에 노출되지 않은 모집단의 유병률은 일반 모집단의 유병률과 동일하다고 가정할 수 있다. 그 후, 영국의 55세에서 59세 사이이며 고선량 이온화 방사선에 노출된 여성은 100,000년에 588세에서 1.120세 사이(즉, 0.6퍼센트에서 1.1퍼센트 사이)의 1년 동안 유방암에 걸릴 위험이 있다고 추정할 수 있다.
다중 위험 요인
이론적으로, 복수의 위험요인이 존재하는 경우의 총 위험은 각각의 상대적 위험과 곱하여 대략 추정할 수 있지만, 일반적으로 우도비를 사용하는 것보다 훨씬 정확성이 떨어지며, 예를 들어, 소스 da를 변환하는 것에 비해 상대적 위험만 주어졌을 때 수행하기가 훨씬 쉽기 때문에 일반적으로 행해진다.민감도 및 특수성에 대한 평가 및 우도비별로 계산한다. 마찬가지로 문헌의 우도비 대신 상대적 위험이 주어지는 경우가 많은데 전자가 더 직관적이기 때문이다. 상대위험을 곱한 부정확성의 원인은 다음과 같다.
- 상대적 위험은 기준 그룹의 조건 유병률(우도비 대비, 그렇지 않음)에 의해 영향을 받는데, 이 문제는 시험 후 확률의 유효성이 기준 그룹의 유병률과 개인에 대한 사전 시험 확률 간의 차이를 증가시키면서 덜 유효하게 된다는 결과를 낳는다. 알려진 위험 요소 또는 개인에 대한 이전의 테스트는 거의 항상 그러한 차이를 포함하며, 여러 위험 요소 또는 검정의 총 영향을 추정할 때 상대적 위험을 사용하는 유효성을 감소시킨다. 대부분의 의사는 시험 결과를 해석할 때 그러한 유병률 차이를 적절히 고려하지 않으며, 이는 불필요한 시험과 진단 오류를 야기할 수 있다.[8]
- 양성 시험만 고려할 때 여러 상대적 위험을 곱하는 부정확성의 또 다른 원인은 우도비 사용과 비교하여 총 위험을 과대평가하는 경향이 있다는 것이다. 이러한 과대 추정은 총 리스크가 100%를 넘을 수 없다는 사실을 보상할 수 있는 방법이 없는 것으로 설명할 수 있다. 이러한 과대 추정은 작은 위험에는 오히려 작지만 높은 가치에 대해서는 높아진다. 예를 들어, 영국의 여성에서 40세 미만의 나이에 유방암에 걸릴 위험은 [9]약 2%로 추정할 수 있다. 또한 아슈케나지 유태인에 대한 연구는 BRCA1의 돌연변이는 40세 미만 여성의 유방암 발병 위험 21.6을, BRCA2의 돌연변이는 40세 미만 여성의 유방암 발병 위험 3.3을 상대적 위험으로 내포한다고 밝혔다.[10] 이러한 데이터로부터 BRCA1 돌연변이를 가진 여성은 40세 미만의 나이에 유방암에 걸릴 위험이 약 40%에 달하고, BRCA2 돌연변이를 가진 여성은 약 6%에 이를 것으로 추정할 수 있다. 그러나 BRCA1 돌연변이와 BRCA2 돌연변이를 둘 다 갖는 다소 실현 가능성이 낮은 상황에서 단순히 상대적 위험과 곱하기만 하면 40세 이전에 유방암 발병률이 140%를 넘을 수 있는 위험성이 발생하는데, 이는 현실적으로는 도저히 정확할 수 없다.
과대평가(상술된 래터) 효과는 위험은 오즈로, 상대 위험은 오즈비로 변환하여 보상할 수 있다. 그러나 이는 개인의 시험 전 확률과 기준 그룹의 유병률 간의 차이에 대한 (이전에 언급된) 영향을 보상하지 않는다.
위의 두 가지 부정확성 원인을 모두 보상하는 방법은 다변량 회귀 분석을 통해 상대적 위험을 설정하는 것이다. 그러나 유효성을 유지하기 위해서는 이와 같이 설정된 상대적 위험과 동일한 회귀 분석의 다른 모든 위험 요인을 곱해야 하며 회귀 분석 이외의 다른 요인을 추가하지 않아야 한다.
또한 여러 상대적 위험을 곱하면 우도비를 사용할 때와 마찬가지로 포함된 위험 요인의 중요한 중복이 누락될 위험도 동일하다. 또한 서로 다른 위험 요인은 시너지 효과를 낼 수 있는데, 예를 들어, 두 요인 모두 개별적으로 상대 위험이 2인 2인 경우 모두 존재할 때 총 상대 위험이 6인 경우 또는 서로 억제할 수 있으며, 이는 우도비 사용에 설명된 간섭과 다소 유사하다.
진단 기준 및 임상 예측 규칙에 따라
대부분의 주요 질병은 진단 기준 및/또는 임상 예측 규칙을 확립했다. 진단 기준이나 임상 예측 규칙의 확립은 관심 조건의 확률을 추정하는 데 중요한 것으로 간주되는 많은 시험에 대한 종합적인 평가로 구성되며, 때로는 그것을 하위 그룹으로 나누는 방법과 조건의 치료 시기와 방법을 포함하기도 한다. 이러한 설정에는 상대적 위험뿐만 아니라 예측 값, 우도 비율의 사용이 포함될 수 있다.
예를 들어 전신 루푸스 에리테마토스에 대한 ACR 기준은 진단을 11개 소견 중 최소 4개 소견의 존재로 정의하며, 각 소견은 자체 민감도와 특수성을 가진 시험의 목표값으로 간주할 수 있다. 이 경우, 예를 들어 이들 대상 매개변수 사이의 간섭 및 대상 매개변수의 중첩과 관련하여 조합하여 사용할 때 이러한 대상 매개변수에 대한 시험의 평가가 있어, i의 우도비를 이용하여 질병의 확률을 계산하려 할 경우 발생할 수 있는 부정확성을 방지하고자 노력했다.무배당 시험 따라서 어떤 조건에 대한 진단 기준이 확립된 경우, 일반적으로 이러한 기준의 맥락에서 해당 조건에 대한 시험 후 확률을 해석하는 것이 가장 적절하다.
또한 나이, 성별, 혈중 지질, 혈압 및 흡연과 같은 여러 위험 요인을 사용하여 관상동맥 심장 질환 결과의 위험을 추정하기 위한 온라인 도구[1]와 같이 여러 위험 요인의 결합된 위험을 추정하기 위한 위험 평가 도구가 있다.ng 각 위험 요인의 개별 상대적 위험.
그러나 경험이 풍부한 의사는 개별 위험 요소와 수행된 시험의 성과를 포함하여 앞에서 설명한 다른 방법 외에 기준과 규칙을 포함하여 광범위한 검토로 시험 후 확률(및 시험의 동기를 부여하는 작용)을 추정할 수 있다.
시험 전 및 시험 후 확률의 임상적 사용
임상적으로 유용한 매개변수는 시험 전 확률과 시험 후 확률 사이의 절대(상대성이 아닌 것, 음성이 아닌 것) 차이를 다음과 같이 계산한다.
절대 차이 = (시험 전 확률) - (시험 후 확률)
그러한 절대적 차이의 주요 요인은 예를 들어 민감도 및 특수성 또는 우도 비율의 관점에서 설명될 수 있는 것과 같이 시험 자체의 검정력이다. 또 다른 요인은 시험 전 확률로, 시험 전 확률이 낮아져 절대적 차이가 더 낮게 나타나며, 그 결과 매우 강력한 시험이라도 (다른 지시 기호가 없는 희귀질환과 같은) 개인의 매우 가능성이 없는 조건에 대해 낮은 절대적 차이를 달성하지만, 다른 한편으로, 그러한 차이는 e이다.저전력 정맥 검사는 매우 의심스러운 조건에서 큰 차이를 만들 수 있다.
이러한 의미에서 확률은 차등 진단 절차의 종단-상대 확률과 같이 시험의 주요 대상이 아닌 조건의 맥락에서도 고려할 필요가 있을 수 있다.
절대적 차이는 다음과 같이 대략적으로 추정할 수 있다.
= ( b - i)- }-{t 여기서:

- b는n 의료 검사를 수행할 때의 순이익이다.
- λp는 시험 전/후 조건(질병 등) 확률의 절대적 차이다.
- r은i 개입의 변화(예: "치료 없음"에서 "저임약 치료의 중단"으로 변경)를 초래할 확률 차이가 어느 정도일 것으로 예상되는지의 비율이다.
- b는i 개인에 대한 개입의 변화의 이점이다.
- h는i 치료의 부작용과 같은 개인에 대한 개입의 변화의 해악이다.
- h는t 시험 자체로 인한 해이다.
이 공식에서 유익성 또는 위해성을 구성하는 것은 크게 개인 및 문화적 가치에 따라 다르지만, 일반적인 결론은 여전히 도출될 수 있다. 예를 들어, 건강검사의 유일한 기대 효과는 한 질환을 다른 질병보다 더 가능성이 높은 것으로 만드는 것이지만, 두 질환이 동일한 치료(또는 둘 다 치료할 수 없음)를 가지고 있다면, ri = 0이고 검사는 기본적으로 개인에게 아무런 유익이 없다.
건강검사의 실시 여부에 영향을 미치는 추가 요인: 검사의 비용, 추가 검사의 가용성, 후속 검사에 대한 잠재적 간섭(예: 소리가 장내 활동을 유발하는 복부 팰프레이션과 같이 이후의 복부 배양에 방해가 될 수 있음), 소요 시간을 포함한다. 시험 또는 기타 실무적 또는 관리적 측면의 경우. 또한, 검사 대상 개인에게 이롭지 않더라도, 그 결과는 다른 개인에 대한 건강 관리를 개선하기 위해 통계 작성에 유용할 수 있다.
주관성
시험 전/후 확률은 실제로 개인이 (확률이 항상 100%인 상태에서) 조건을 갖거나 갖지 않거나 둘 중 하나라는 사실에 근거하여 주관적이므로, 개인에 대한 사전/사후 확률은 오히려 당면한 진단에 관여하는 사람들의 마음 속에 심리 현상으로 간주될 수 있다.
참고 항목
- 부정확성 및 부정확성의 일반적인 원인을 포함한 진단 테스트 해석
참조
- ^ Mark Ebell의 증거 기반 온라인 코스. 조지아 대학의 공중 보건 대학. 2011년 8월 검색됨
- ^ a b c d 가능성 비율 2010년 12월 22일 웨이백 머신에 CEBM(증거 기반 의학 센터)에서 보관. 마지막 페이지 편집: 2009년 2월 1일 예제에서 사용할 경우, 일반적인 공식은 참조에서 추출되는 반면 예제 번호는 서로 다르다.
- ^ 이미지에서 가져온 매개 변수: Zhang W, Doherty M, Pascual E, et al. (October 2006). "EULAR evidence based recommendations for gout. Part I: Diagnosis. Report of a task force of the Standing Committee for International Clinical Studies Including Therapeutics (ESCISIT)". Ann. Rheum. Dis. 65 (10): 1301–11. doi:10.1136/ard.2006.055251. PMC 1798330. PMID 16707533.
- ^ Brown MD, Reeves MJ (2003). "Evidence-based emergency medicine/skills for evidence-based emergency care. Interval likelihood ratios: another advantage for the evidence-based diagnostician". Ann Emerg Med. 42 (2): 292–297. doi:10.1067/mem.2003.274. PMID 12883521.
- ^ 750페이지(10장):
- ^ 그림 1.1: 유방암(C50), 연간 평균 신규 환자 수 및 연령별 발병률, 영국, 2006-2008 유방암 - 영국 발생 통계 2012년 5월 14일 영국 암 연구소의 웨이백 기계에 보관된 Excel 차트. 섹션 업데이트/2007/11.
- ^ ACS (2005). "Breast Cancer Facts & Figures 2005–2006" (PDF). Archived from the original (PDF) on 13 June 2007. Retrieved 26 April 2007.
- ^ Agoritsas, T.; Courvoisier, D. S.; Combescure, C.; Deom, M.; Perneger, T. V. (2010). "Does Prevalence Matter to Physicians in Estimating Post-test Probability of Disease? A Randomized Trial". Journal of General Internal Medicine. 26 (4): 373–378. doi:10.1007/s11606-010-1540-5. PMC 3055966. PMID 21053091.
- ^ 2%는 39세 이하의 여성에서 100,000명당 2.075명의 누적 발병률에서, 위의 Cancer Research UK reference에서 제공되었다.
- ^ Satagopan, J. M.; Offit, K.; Foulkes, W.; Robson, M. E.; Wacholder, S.; Eng, C. M.; Karp, S. E.; Begg, C. B. (2001). "The lifetime risks of breast cancer in Ashkenazi Jewish carriers of BRCA1 and BRCA2 mutations". Cancer Epidemiology, Biomarkers & Prevention. 10 (5): 467–473. PMID 11352856.



{kind=link}