인터프로
InterPro| 콘텐츠 | |
|---|---|
| 묘사 | 인터프로(InterPro)는 단백질 서열을 기능적으로 분석해 단백질 패밀리로 분류하는 동시에 도메인과 기능 부위의 존재를 예측한다. |
| 연락 | |
| 연구소 | 엠블 |
| 실험실. | 유럽생물정보학연구소 |
| 주요 인용문 | InterPro 단백질 패밀리 및 도메인 데이터베이스: 20년 이상[1] |
| 발매일 | 1999 |
| 접근 | |
| 웹 사이트 | www |
| 다운로드 URL | ftp.ebi.ac.uk/pub/databases/interpro/ |
| 여러가지 종류의 | |
| 데이터 릴리즈 빈도수. | 8주간 |
| 버전 | 83.0 (2020년 12월 2일, 전 ( |
InterPro는 단백질 패밀리, 단백질 도메인 및 기능 부위의 데이터베이스로,[3][4] 알려진 단백질에서 발견되는 식별 가능한 특징을 기능적으로 특징짓기 위해 새로운 단백질[2] 배열에 적용할 수 있습니다.
InterPro의 내용은 진단 시그니처와 이들이 유의하게 일치하는 단백질로 구성됩니다.시그니처는 단백질 패밀리, 도메인 또는 사이트를 기술하는 모델(정규 표현과 같은 단순한 유형 또는 숨겨진 마르코프 모델과 같은 더 복잡한 유형)로 구성됩니다.모델은 알려진 패밀리 또는 도메인의 아미노산 배열로부터 구축되며, 그것들을 분류하기 위해 알려지지 않은 배열(예: 새로운 게놈 배열에서 발생하는 배열)을 검색하는데 사용됩니다.InterPro의 각 구성원 데이터베이스는 매우 높은 수준의 구조 기반 분류(SUPERFAILY 및 CATH-Gene3D)에서 매우 구체적인 하위 분류(PRINTS 및 PANTER)에 이르기까지 다양한 틈새 시장에 기여한다.
InterPro의 의도는 단백질 분류를 위한 원스톱샵을 제공하는 것이다.여기서 다른 멤버 데이터베이스에 의해 생성된 모든 시그니처는 InterPro 데이터베이스 내의 엔트리에 배치된다.동등한 도메인, 사이트 또는 패밀리를 나타내는 시그니처는 같은 엔트리에 포함되며 엔트리를 서로 관련지을 수도 있습니다.가능한 경우 설명, 일관된 이름 및 GO(Gene Ontology) 용어와 같은 추가 정보가 각 항목과 관련되어 있습니다.
InterPro에 포함된 데이터
InterPro에는 단백질, 시그니처('방법' 또는 '모델'이라고도 함) 및 엔트리의 3가지 주요 엔티티가 있습니다.UniProtKB의 단백질은 InterPro의 중심 단백질 실체이기도 하다.어떤 시그니처가 이들 단백질과 유의하게 일치하는지에 대한 정보는 UniProtKB에 의해 시퀀스가 공개되고 이러한 결과가 일반에 공개될 때 계산된다(아래 참조).단백질에 대한 시그니처의 일치는 시그니처가 InterPro 엔트리에 어떻게 통합되는지를 결정하는 것입니다.일치된 단백질 세트의 비교 오버랩과 시그니처의 시퀀스에서의 일치 위치가 관련성의 지표로 사용됩니다.충분한 품질의 시그니처만 InterPro에 통합됩니다.버전 81.0(2020년 8월 21일 출시) 현재, InterPro 엔트리는 UniProtKB에서 발견된 잔류물의 73.9%에 주석을 달았고,[5] 통합 보류 중인 서명에 의해 주석이 추가된 다른 9.2%에 달했습니다.

InterPro는 또한 UniParc 및 UniMES 데이터베이스에 포함된 스플라이스 변형 및 단백질에 대한 데이터를 포함합니다.
InterPro 컨소시엄 구성원 데이터베이스
InterPro로부터의 시그니처는, 13개의 「멤버 데이타베이스」로부터 취득되고 있습니다.이러한 시그니처는 다음과 같습니다.
- CATH-Gene3d
- 단백질 패밀리와 도메인 아키텍처를 완전한 게놈으로 기술합니다.단백질 패밀리는 마르코프 클러스터링 알고리즘을 사용하여 형성되며, 이어서 배열 동일성에 따른 다중 링크 클러스터링이 이루어진다.예측 구조 및 시퀀스 도메인의 매핑은 CATH 및 Pfam 도메인을 나타내는 숨겨진 마르코프 모델 라이브러리를 사용하여 수행된다.기능적 주석은 여러 자원의 단백질에 제공된다.도메인 아키텍처의 기능 예측 및 분석은 Gene3D 웹사이트에서 이용할 수 있습니다.
- CDD
- Conserved Domain Database는 고대 도메인과 전장 단백질을 위한 주석 다중 배열 모델의 모음으로 구성된 단백질 주석 리소스입니다.이것들은 RPS-BLAST를 통해 단백질 시퀀스에서 보존된 도메인을 빠르게 식별하기 위한 위치 고유 점수 매트릭스(PSSM)로 이용할 수 있다.
- HAMAP
- 미생물 프로테옴의 고품질 자동 및 수동 주석을 나타냅니다.HAMAP 프로파일은 전문 큐레이터에 의해 수동으로 생성되며, 잘 보존된 박테리아, 고고학 및 플라스티드로 인코딩된 단백질(예: 엽록체, 시아넬, 아포코플라스트, 비광합성 플라스티드) 단백질 패밀리 또는 하위 패밀리의 일부인 단백질을 식별한다.
- 모바일 데이터베이스
- MobiDB는 단백질에 내재된 장애에 주석을 다는 데이터베이스이다.
- 팬더
- PANTER는 인간의 전문지식을 사용하여 기능적으로 관련된 아족으로 세분화된 단백질군의 대규모 집합이다.이러한 아족은 단백질 패밀리 내 특정 기능의 분리를 모델링하여 기능(인간 큐레이션 분자 기능, 생물학적 과정 분류 및 경로도)과 보다 정확한 연관성뿐만 아니라 기능 특이성에 중요한 아미노산의 추론을 가능하게 한다.숨겨진 마르코프 모델(HM)은 추가 단백질 서열을 분류하기 위해 각 패밀리 및 하위 패밀리에 대해 구축된다.
- 팜
- 많은 공통 단백질 도메인과 패밀리를 포함하는 다중 배열 정렬과 숨겨진 마르코프 모델의 대규모 컬렉션입니다.
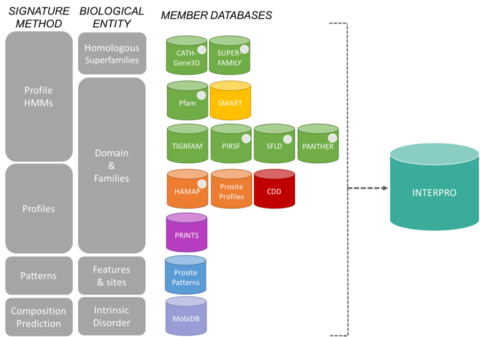 InterPro 컨소시엄의 13개 회원 데이터베이스는 그들의 대표 구축 방법 [6]및 그들이 초점을 맞춘 생물학적 실체에 따라 그룹화된다.
InterPro 컨소시엄의 13개 회원 데이터베이스는 그들의 대표 구축 방법 [6]및 그들이 초점을 맞춘 생물학적 실체에 따라 그룹화된다. - PIRSF
- 단백질 분류 시스템은 전장 단백질과 도메인의 진화적 관계를 반영하는 슈퍼패밀리에서 서브패밀리에 이르기까지 다양한 수준의 배열 다양성을 가진 네트워크이다.일차 PIRSF 분류 단위는 동형 계열이며, 그 구성원은 동형(공통 조상으로부터 진화)과 동형(전체 길이 시퀀스 유사성과 공통 도메인 아키텍처를 공유함)이다.
- 인쇄하다
- PRINTS는 단백질 지문의 총집합이다.지문은 단백질 패밀리를 특징짓는 데 사용되는 보존된 모티브의 그룹이며, UniProt의 반복 스캔을 통해 진단 능력이 향상됩니다.일반적으로 모티브는 겹치지 않고 시퀀스를 따라 분리되지만 3D 공간에서 연속될 수 있습니다.지문은 단백질 접힘과 기능을 단일 모티브보다 더 유연하고 강력하게 부호화할 수 있으며, 모티브 인접 모티브가 제공하는 상호 컨텍스트에서 파생된 완전한 진단 능력입니다.
- 프로 사이트
- PROSITE는 단백질 패밀리 및 도메인의 데이터베이스입니다.이것은 생물학적으로 중요한 부위, 패턴 및 프로파일로 구성되어 있으며, 새로운 배열이 어떤 알려진 단백질 패밀리에 속하는지(있는 경우) 신뢰성 있게 식별할 수 있도록 도와준다.
- 스마트
- Simple Modular Architecture Research Tool 유전적으로 모바일 도메인의 식별과 주석 달기 및 도메인 아키텍처 분석을 가능하게 합니다.시그널링, 세포외 및 염색질 관련 단백질에서 발견된 800개 이상의 도메인 패밀리가 검출된다.이러한 도메인은 Phyletic 분포, 기능 등급, 3차 구조 및 기능적으로 중요한 잔류물과 관련하여 광범위하게 주석을 달았다.
- 슈퍼 패밀리
- SUPERFAILY는 알려진 구조의 모든 단백질을 나타내는 프로파일 숨겨진 마르코프 모델의 라이브러리입니다.라이브러리는 단백질의 SCOP 분류에 기초하고 있습니다.각 모델은 SCOP 도메인에 대응하며 도메인이 속한 전체 SCOP 슈퍼 패밀리를 나타내는 것을 목표로 합니다.SUPER FAMILY는 완전히 배열된 모든 게놈에 대한 구조적 할당을 수행하기 위해 사용되어 왔다.
- SFLD
- 특정 배열 구조 특성과 특정 화학적 기능을 관련짓는 효소의 계층적 분류.
- TIGRFAMs
- TIGRFAMs는 배열 호몰로지를 기반으로 기능적으로 관련된 단백질을 식별하기 위한 도구를 제공하는 큐레이티드 다중 배열, 숨겨진 마르코프 모델(HM) 및 주석을 특징으로 하는 단백질 패밀리 모음이다."등가"인 이러한 항목은 기능과 관련하여 보존된 상동성 단백질을 그룹화한다.

데이터형
InterPro는 컨소시엄의 다양한 구성원이 제공하는 7가지 유형의 데이터로 구성됩니다.
| 데이터형 | 묘사 | 기여 데이터베이스 |
|---|---|---|
| InterPro 엔트리 | 하나 이상의 서명을 사용하여 예측된 단백질의 구조 및/또는 기능 영역 | 13개 멤버 데이터베이스 모두 |
| 멤버 데이터베이스 시그니처 | 멤버 데이터베이스의 시그니처여기에는 InterPro에 통합된 시그니처와 통합되지 않은 시그니처가 포함됩니다. | 13개 멤버 데이터베이스 모두 |
| 단백질 | 단백질 배열 | UniProtKB(Swiss-Prot 및 TrEMBL) |
| 프로테옴 | 단일 유기체에 속하는 단백질 집합 | UniProtKB |
| 구조. | 단백질의 3차원 구조 | PDBe |
| 분류법 | 단백질 분류 정보 | UniProtKB |
| 세트 | 진화 관련 패밀리 그룹 | Pfam, CDD |

InterPro 엔트리 타입
InterPro 엔트리는 다음 5가지 유형으로 나눌 수 있습니다.
- 상동성 슈퍼패밀리: 비록 배열이 매우 유사하지 않더라도 구조적인 유사성에서 볼 수 있듯이 공통의 진화적 기원을 공유하는 단백질 그룹.이러한 엔트리는 특히 CATH-Gene3D와 SUPERFAILY라는2개의 멤버 데이터베이스에서만 제공됩니다.
- 패밀리: 구조적 유사성, 관련 기능 또는 배열 호몰로지를 통해 결정되는 공통 진화 기원을 가진 단백질 그룹.
- 도메인: 특정 기능, 구조 또는 배열을 가진 단백질의 고유한 단위.
- 반복: 보통 50개 이하의 아미노산 배열로, 단백질에서 여러 번 반복되는 경향이 있습니다.
- 사이트: 적어도 하나의 아미노산이 보존된 짧은 아미노산 배열.여기에는 변환 후 수정 사이트, 보존 사이트, 바인딩 사이트 및 활성 사이트가 포함됩니다.
접근
데이터베이스는 웹 서버를 통한 텍스트 및 시퀀스 기반 검색 및 익명 FTP를 통한 다운로드에 사용할 수 있습니다.다른 EBI 데이터베이스와 마찬가지로 콘텐츠는 "개인과 목적에 따라"[8] 사용할 수 있기 때문에 퍼블릭도메인 내에 있습니다.InterPro는 일반적으로 동일한 단백질의 UniProtKB 출시 후 하루 이내에 8주마다 데이터를 일반에 공개하는 것을 목표로 합니다.
InterPro 애플리케이션 프로그래밍 인터페이스(API)
InterPro는 Json 형식의 모든 InterPro 엔트리와 관련 엔트리에 [9]프로그래밍 방식으로 액세스할 수 있는 API를 제공합니다.API에는 엔트리, 단백질, 구조, 분류법, 프로테옴, 세트 등 다양한 InterPro 데이터 유형에 대응하는6개의 주요 엔드포인트가 있습니다.
인터프로스캔
InterProScan은 멤버 데이터베이스 시그니처에 대해 시퀀스를 스캔할 수 있는 소프트웨어 패키지입니다.사용자는 이 시그니처 스캔 소프트웨어를 사용하여 새로운 뉴클레오티드 또는 단백질 시퀀스를 [10]기능적으로 특징지을 수 있습니다.InterProScan은 관심 [11][12]게놈의 "퍼스트 패스" 특성을 얻기 위해 게놈 프로젝트에서 자주 사용됩니다.2020년 12월[update] 현재 InterProScan의 퍼블릭 버전(v5.x)은 Java [13]기반 아키텍처를 사용합니다.소프트웨어 패키지는 현재 64비트 리눅스 운영 체제에서만 지원됩니다.
InterProScan은 다른 많은 EMBL-EBI 생물정보학 도구와 함께 RESTful 및 SOAP Web Services API를 [14]사용하여 프로그래밍 방식으로 액세스할 수도 있습니다.
「 」를 참조해 주세요.
레퍼런스
- ^ Blum M, Chang HY, Chuguransky S, Grego T, Kandasaamy S, Mitchell A, et al. (November 2020). "The InterPro protein families and domains database: 20 years on". Nucleic Acids Research. 49 (D1): D344–D354. doi:10.1093/nar/gkaa977. PMC 7778928. PMID 33156333.
- ^ Hunter S, Jones P, Mitchell A, Apweiler R, Attwood TK, Bateman A, et al. (January 2012). "InterPro in 2011: new developments in the family and domain prediction database". Nucleic Acids Research. 40 (Database issue): D306-12. doi:10.1093/nar/gkr948. PMC 3245097. PMID 22096229.
- ^ Apweiler R, Attwood TK, Bairoch A, Bateman A, Birney E, Biswas M, et al. (January 2001). "The InterPro database, an integrated documentation resource for protein families, domains and functional sites". Nucleic Acids Research. 29 (1): 37–40. doi:10.1093/nar/29.1.37. PMC 29841. PMID 11125043.
- ^ Apweiler R, Attwood TK, Bairoch A, Bateman A, Birney E, Biswas M, et al. (December 2000). "InterPro--an integrated documentation resource for protein families, domains and functional sites". Bioinformatics. 16 (12): 1145–50. doi:10.1093/bioinformatics/16.12.1145. PMID 11159333.
- ^ a b Blum, Matthias; Chang, Hsin-Yu; Chuguransky, Sara; Grego, Tiago; Kandasaamy, Swaathi; Mitchell, Alex; Nuka, Gift; Paysan-Lafosse, Typhaine; Qureshi, Matloob; Raj, Shriya; Richardson, Lorna (2020-11-06). "The InterPro protein families and domains database: 20 years on". Nucleic Acids Research. 49 (D1): D344–D354. doi:10.1093/nar/gkaa977. ISSN 0305-1048. PMC 7778928. PMID 33156333.
- ^ EMBL-EBI. "Where does the data come from? InterPro". Retrieved 2020-12-04.
- ^ EMBL-EBI. "InterPro entry types InterPro". Retrieved 2020-12-04.
- ^ "Terms of Use for EMBL-EBI Services European Bioinformatics Institute".
- ^ "How to download InterPro data? — InterPro Documentation". interpro-documentation.readthedocs.io. Retrieved 2020-12-04.
- ^ Quevillon E, Silventoinen V, Pillai S, Harte N, Mulder N, Apweiler R, Lopez R (July 2005). "InterProScan: protein domains identifier" (Free full text). Nucleic Acids Research. 33 (Web Server issue): W116-20. doi:10.1093/nar/gki442. PMC 1160203. PMID 15980438.
- ^ Lander ES, Linton LM, Birren B, Nusbaum C, Zody MC, Baldwin J, et al. (February 2001). "Initial sequencing and analysis of the human genome" (PDF). Nature. 409 (6822): 860–921. Bibcode:2001Natur.409..860L. doi:10.1038/35057062. PMID 11237011.
- ^ Holt RA, Subramanian GM, Halpern A, Sutton GG, Charlab R, Nusskern DR, et al. (October 2002). "The genome sequence of the malaria mosquito Anopheles gambiae". Science. 298 (5591): 129–49. Bibcode:2002Sci...298..129H. CiteSeerX 10.1.1.149.9058. doi:10.1126/science.1076181. PMID 12364791. S2CID 4512225.
- ^ Jones P, Binns D, Chang HY, Fraser M, Li W, McAnulla C, et al. (May 2014). "InterProScan 5: genome-scale protein function classification". Bioinformatics. 30 (9): 1236–40. doi:10.1093/bioinformatics/btu031. PMC 3998142. PMID 24451626.
- ^ Madeira F, Park YM, Lee J, Buso N, Gur T, Madhusoodanan N, et al. (July 2019). "The EMBL-EBI search and sequence analysis tools APIs in 2019". Nucleic Acids Research. 47 (W1): W636–W641. doi:10.1093/nar/gkz268. PMC 6602479. PMID 30976793.
외부 링크
- 공식 웹사이트 - 웹 서버


